


7. TraversĂŠe des tables et des chaĂŽnes▲
Ce chapitre dÊcrit la façon dont les paquets traversent les diffÊrentes chaÎnes, et dans quel ordre. De même, il explique l'ordre dans lequel les tables sont traversÊes. Vous percevrez l'importance de ce fonctionnement plus loin, lors de l'Êcriture de vos propres règles. D'autres points seront examinÊs, liÊs à des ÊlÊments dÊpendants du noyau, car ils entrent Êgalement en considÊration dans ce chapitre. Entre autres, les diffÊrentes dÊcisions de routage. C'est particulièrement utile si vous voulez Êcrire des règles pour iptables qui peuvent modifier les consignes/règles de routage des paquets, c.-à -d.. pourquoi et comment les paquets sont routÊs; le DNAT et le SNAT sont des exemples caractÊristiques. Bien sÝr, il ne faut pas oublier les bits de TOS.
7-1. GĂŠnĂŠralitĂŠs▲
Quand un paquet arrive pour la première fois dans un pare-feu, il rencontre le niveau matÊriel, puis il est recueilli par le pilote de pÊriphÊrique appropriÊ au sein du noyau. Ensuite, le paquet enchaÎne une succession d'Êtapes dans le noyau, avant d'être envoyÊ à l'application adÊquate (localement), ou expÊdiÊ à un autre hôte - ou quoi que ce soit d'autre.
D'abord, analysons un paquet destinÊ à la machine locale. Il enchaÎne les Êtapes suivantes avant d'être rÊellement dÊlivrÊ à l'application qui le reçoit :
Tableau 6.1. Hôte local destinataire (votre propre machine)
| Ătape | Table | ChaĂŽne | Commentaire |
| 1 |  |  | Sur le câble (ex. Internet) |
| 2 | Â | Â | Arrive sur l'interface (ex. eth0) |
| 3 | raw | PREROUTING | Cette chaĂŽne sert normalement Ă modifier les paquets, i.e. changer les bits de TOS, etc. |
| 4 | Â | Â | Lors du contrĂ´le de code de connexion comme indiquĂŠ dans le chapitre La machine d'ĂŠtatLa machine d'ĂŠtat. |
| 5 | mangle | PREROUTING | ChaĂŽne principalement utilisĂŠe pour modifier les paquets, i-e, changement de TOS, etc. |
| 6 | nat | PREROUTING | Cette chaĂŽne sert principalement au DNAT. Ăvitez de filtrer dans cette chaĂŽne puisqu'elle est court-circuitĂŠe dans certains cas. |
| 7 |  |  | DÊcision de routage, i.e. le paquet est-il destinÊ à notre hôte local, doit-il être rÊexpÊdiÊ et oÚ ? |
| 8 | mangle | INPUT | Ici, il atteint la chaÎne INPUT de la table mangle. Cette chaÎne permet de modifier les paquets, après leur routage, mais avant qu'ils soient rÊellement envoyÊs au processus de la machine. |
| 9 | filter | INPUT | C'est l'endroit oĂš est effectuĂŠ le filtrage du trafic entrant Ă destination de la machine locale. Notez bien que tous les paquets entrants et destinĂŠs Ă votre hĂ´te passent par cette chaĂŽne, et ceci, quelles que soient leur interface ou leur provenance d'origine. |
| 10 | Â | Â | Processus/application local (i.e. programme client/serveur). |
Remarquez que cette fois, le paquet est transmis Ă travers la chaĂŽne INPUT au lieu de la chaĂŽne FORWARD. C'est parfaitement logique. Et c'est certainement la seule chose logique Ă vos yeux dans le parcours des tables et des chaĂŽnes pour le moment, mais si vous continuez d'y rĂŠflĂŠchir, vous trouverez ceci de plus en plus clair au fur et Ă mesure.
Ă prĂŠsent, analysons les paquets sortant de notre hĂ´te local et les ĂŠtapes qu'ils enchaĂŽnent.
Tableau 6.2. Hôte local source (votre propre machine)
| Ătape | Table | ChaĂŽne | Commentaire |
| 1 | Â | Â | Processus/application local (i.e. programme client/serveur). |
| 2 | Â | Â | DĂŠcision de routage. Quelle adresse source doit ĂŞtre utilisĂŠe, quelle interface de sortie, et d'autres informations nĂŠcessaires qui doivent ĂŞtre rĂŠunies. |
| 3 | raw | OUTPUT | C'est l'endroit oÚ le traçage de connexion prend place pour les paquets gÊnÊrÊs localement. Vous pouvez marquer les connexions pour qu'elles ne soient pas tracÊes par exemple. |
| 4 |  |  | C'est ici que le traçage de connexion se situe pour les paquets gÊnÊrÊs localement, par exemple les changements d'Êtat, etc. Voir le chapitre LaLa machine d'Êtat pour plus d'informations. |
| 5 | mangle | OUTPUT | C'est lĂ oĂš les paquets sont modifiĂŠs. Il est conseillĂŠ de ne pas filtrer dans cette chaĂŽne, Ă cause de certains effets de bord. |
| 6 | nat | OUTPUT | Cette chaĂŽne permet de faire du NAT sur des paquets sortant du pare-feu. |
| 7 |  |  | DÊcision de routage, comment les modifications des mangle et nat prÊcÊdents peuvent avoir changÊ la façon dont les paquets seront routÊs. |
| 8 | filter | OUTPUT | C'est de lĂ que les paquets sortent de l'hĂ´te local. |
| 9 | mangle | POSTROUTING | La chaÎne POSTROUTING de la table mangle est principalement utilisÊe lorsqu'on souhaite modifier des paquets avant qu'ils quittent la machine, mais après les dÊcisions de routage. Cette chaÎne est rencontrÊe d'une part par les paquets qui ne font que transiter par le pare-feu, d'autre part par les paquets crÊÊs par le pare-feu lui-même. |
| 10 | nat | POSTROUTING | C'est ici qu'est effectuĂŠ le SNAT. Il est conseillĂŠ de ne pas filtrer Ă cet endroit Ă cause des effets de bord, certains paquets peuvent se faufiler mĂŞme si un comportement par dĂŠfaut a ĂŠtĂŠ dĂŠfini pour la cible DROP. |
| 11 | Â | Â | Sort par une certaine interface (ex. eth0). |
| 12 |  |  | Sur le câble (ex. Internet). |
Dans cet exemple, on suppose que le paquet est destinÊ à un autre hôte sur un autre rÊseau. Le paquet parcourt les diffÊrentes Êtapes de la façon suivante :
Tableau 6.3. Paquets redirigÊs
| Ătape | Table | ChaĂŽne | Commentaire |
| 1 |  |  | Sur le câble (ex. Internet). |
| 2 | Â | Â | Arrive sur l'interface (ex. eth0). |
| 3 | raw | PREROUTING | Ici vous pouvez placer une connexion qui ne sera pas interprÊtÊe par le système de traçage de connexion. |
| 4 |  |  | C'est ici que le traçage de connexion gÊnÊrÊ non localement prend place, nous verrons cela dans le chapitre La machine d'ÊtatLa machine d'Êtat. |
| 5 | mangle | PREROUTING | Cette chaĂŽne est typiquement utilisĂŠe pour modifier les paquets, i.e. changer les bits de TOS, etc. |
| 6 | nat | PREROUTING | Cette chaĂŽne sert principalement Ă rĂŠaliser du DNAT. Le SNAT est effectuĂŠ plus loin. Ăvitez de filtrer dans cette chaĂŽne, car elle peut ĂŞtre court-circuitĂŠe dans certains cas. |
| 7 |  |  | DÊcision de routage, c.-à -d.. le paquet est-il destinÊ à votre hôte local, doit-il être redirigÊ et oÚ ? |
| 8 | mangle | FORWARD | Le paquet est alors envoyÊ à la chaÎne FORWARD de la table mangle. C'est utile pour des besoins très spÊcifiques, lorsque l'on souhaite modifier des paquets après la dÊcision de routage initiale, mais avant la dÊcision de routage finale effectuÊe juste avant l'envoi du paquet. |
| 9 | filter | FORWARD | Le paquet est routÊ vers la chaÎne FORWARD. Seuls les paquets rÊexpÊdiÊs arrivent ici, et c'est ici Êgalement que tout le filtrage est effectuÊ. Notez bien que tout trafic redirigÊ passe par ici (et pas seulement dans un sens), donc vous devez y rÊflÊchir en rÊdigeant vos règles. |
| 10 | mangle | POSTROUTING | Cette chaÎne est employÊe pour des formes particulières de modification de paquets, que l'on veut appliquer postÊrieurement à toutes les dÊcisions de routage, mais toujours sur cette machine. |
| 11 | nat | POSTROUTING | Cette chaĂŽne est employĂŠe principalement pour le SNAT. Ăvitez de faire du filtrage ici, car certains paquets peuvent passer cette chaĂŽne sans ĂŞtre vĂŠrifiĂŠs. C'est aussi l'endroit oĂš l'on fait du masquerading (masquage d'adresse). |
| 12 | Â | Â | Sort par l'interface de sortie (ex. eth1). |
| 13 |  |  | Sort de nouveau par le câble (ex. LAN). |
Comme vous pouvez le constater, il y a de nombreuses ĂŠtapes Ă franchir. Un paquet peut ĂŞtre arrĂŞtĂŠ dans n'importe quelle chaĂŽne d'iptables, et mĂŞme ailleurs s'il est mal formĂŠ. Pourtant, il est intĂŠressant de se pencher sur le sort du paquet vu par iptables. Remarquez qu'aucune chaĂŽne ou table spĂŠcifique n'est dĂŠfinie pour des interfaces diffĂŠrentes, ou quoi que ce soit de semblable. La chaĂŽne FORWARD est systĂŠmatiquement parcourue par les paquets qui sont redirigĂŠs par l'intermĂŠdiaire de ce pare-feu/routeur.
N'utilisez pas la chaÎne INPUT pour filtrer dans le scÊnario prÊcÊdent ! INPUT n'a de sens que pour des paquets destinÊs à votre hôte local, autrement dit qui ne seront routÊs vers aucune autre destination.
Maintenant, vous avez dÊcouvert comment les diffÊrentes chaÎnes sont traversÊes selon trois scÊnarios distincts. On peut en donner une reprÊsentation graphique :
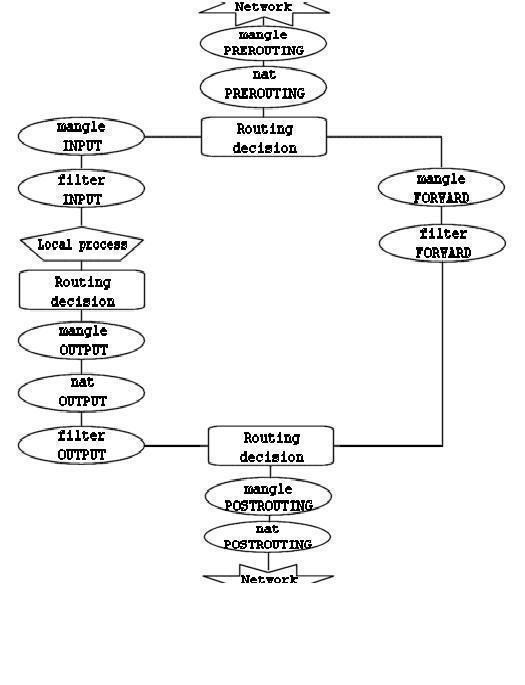
Pour être plus clair, ce dessin mÊrite quelques explications. Si un paquet atteignant la première dÊcision de routage n'est pas destinÊ à la machine locale, il sera orientÊ vers la chaÎne FORWARD. En revanche, s'il est destinÊ à une adresse IP que la machine Êcoute, ce paquet sera envoyÊ vers la chaÎne INPUT, et donc à la machine locale.
Il est important de remarquer que même si des paquets sont destinÊs à la machine locale, leur adresse de destination peut être modifiÊe à l'intÊrieur de la chaÎne PREROUTING par une opÊration de NAT. En effet, puisque ceci a lieu avant la première dÊcision de routage, le paquet ne sera examinÊ qu'après un Êventuel changement. à cause de cette particularitÊ, le routage peut être altÊrÊ avant que la dÊcision de routage ne soit prise. Notez bien que tous les paquets transiteront par l'un ou l'autre des chemins de ce dessin. Si vous rÊalisez du DNAT sur un paquet pour le renvoyer sur le rÊseau duquel il provient, il continuera malgrÊ tout sa route à travers les chaÎnes restantes jusqu'à ce qu'il retourne sur le rÊseau externe.
Si vous pensez avoir besoin d'informations supplÊmentaires, vous pouvez utiliser le script rc.test-iptables.txtrc.test-iptables.txt. Ce script de test devrait vous procurer des règles suffisantes pour expÊrimenter et comprendre de quelle façon les tables et les chaÎnes sont traversÊes.
7-2. La table Mangle▲
Comme il a dĂŠjĂ ĂŠtĂŠ prĂŠcisĂŠ, le rĂ´le principal de cette table devrait ĂŞtre de modifier des paquets. En d'autres termes, vous pouvez utiliser en toute libertĂŠ les correspondances de la table mangle, qui permettent de changer les champs de TOS (type de service), et d'autres.
Vous avez ĂŠtĂŠ suffisamment prĂŠvenus de ne pas utiliser cette table pour effectuer du filtrage; de mĂŞme, les opĂŠrations de DNAT, SNAT ou de masquerading ne fonctionnent pas dans cette table.
Les cibles suivantes sont valides uniquement dans la table mangle. Elles ne doivent pas ĂŞtre utilisĂŠes en dehors de cette table.
- TOS
- TTL
- MARK
- SECMARK
- CONNSECMARK
La cible TOS permet de dĂŠfinir et/ou modifier le champ de Type de Service d'un paquet. C'est utile pour dĂŠfinir des stratĂŠgies rĂŠseau concernant le choix de routage des paquets. Sachez que, d'une part ceci n'a pas ĂŠtĂŠ perfectionnĂŠ, d'autre part ce n'est pas vraiment implĂŠmentĂŠ sur Internet, car la majoritĂŠ des routeurs ne se prĂŠoccupent pas de ce champ, et quelquefois mĂŞme, ils adoptent un comportement erronĂŠ. Bref, ne configurez pas ce champ sur les paquets qui naviguent sur Internet, sauf si vous souhaitez leur appliquer des dĂŠcisions de routage, avec iproute2.
La cible TTL permet de modifier le champ durÊe de vie ou TTL (Time To Live) d'un paquet. Il est possible par exemple de spÊcifier aux paquets d'avoir un champ TTL spÊcifique. Ceci peut se justifier lorsque vous ne souhaitez pas être rejetÊ par certains Fournisseurs d'Accès à Internet (FAI) trop indiscrets. En effet, il existe des FAI qui dÊsapprouvent les utilisateurs branchant plusieurs ordinateurs sur une même connexion, et de fait, quelques-uns de ces FAI sont connus pour vÊrifier si un même hôte gÊnère diffÊrentes valeurs TTL, supposant ainsi que plusieurs machines sont branchÊes sur la même connexion.
La cible MARK permet d'associer des valeurs de marquage particulières aux paquets. Elles peuvent ensuite être identifiÊes par les programmes iproute2 pour appliquer un routage diffÊrent en fonction de l'existence ou de l'absence de telle ou telle marque. On peut ainsi rÊaliser de la restriction de bande passante et de la gestion de prioritÊ (Class Based Queuing).
La cible SECMARK peut être utilisÊe pour placer des marques dans un contexte de sÊcuritÊ sur des paquets dans SELinux ou tout autre système de sÊcuritÊ capable de gÊrer ces marques.
CONNSECMARK sert à copier un contexte de sÊcuritÊ vers ou depuis un simple paquet ou vers une connexion complète. Elle est utilisÊe par SELinux ou autre système de sÊcuritÊ pour affiner cette sÊcuritÊ au niveau connexion.
7-3. La table Nat▲
Cette table devrait être utilisÊe seulement pour effectuer de la traduction d'adresse rÊseau (NAT) sur diffÊrents paquets. Autrement dit, elle ne devrait servir qu'à traduire le champ de l'adresse source d'un paquet ou celui de l'adresse destination. PrÊcisons à nouveau que seul le premier paquet d'un flux rencontrera cette chaÎne. Ensuite, les autres paquets subiront automatiquement le même sort que le premier. Voici les cibles actuelles capables d'accomplir ce genre de choses :
- DNAT
- SNAT
- MASQUERADE
- REDIRECT
La cible DNAT est gÊnÊralement utile dans le cas oÚ vous dÊtenez une adresse IP publique et que vous dÊsirez rediriger les accès vers un pare-feu localisÊ sur un autre hôte (par exemple, dans une zone dÊmilitarisÊe ou DMZ). Concrètement, on change l'adresse de destination du paquet avant de le router à nouveau vers l'hôte dÊsignÊ.
La cible SNAT est quant à elle employÊe pour changer l'adresse de source des paquets. La plupart du temps, vous dissimulerez votre rÊseau local ou votre DMZ, etc. Un très bon exemple serait donnÊ par un pare-feu pour lequel l'adresse externe est connue, mais qui nÊcessite de substituer les adresses IP du rÊseau local avec celle du pare-feu. Avec cette cible, le pare-feu effectuera automatiquement sur les paquets du SNAT dans un sens et du SNAT inverse dans l'autre, rendant possibles les connexions d'un rÊseau local sur Internet. à titre d'exemple, si votre rÊseau utilise la famille d'adresses 192.168.0.0/masque_rÊseau, les paquets envoyÊs sur Internet ne reviendront jamais, parce que l'IANA (institut de rÊgulation des adresses) a considÊrÊ ce rÊseau (avec d'autres) comme privÊ, et a restreint son usage à des LAN isolÊs d'Internet.
La cible MASQUERADE s'utilise exactement de la même façon que la cible SNAT, mais la cible MASQUERADE demande un peu plus de ressources pour s'exÊcuter. L'explication vient du fait que chaque fois qu'un paquet atteint la cible MASQUERADE, il vÊrifie automatiquement l'adresse IP à utiliser, au lieu de se comporter comme la cible SNAT qui se rÊfère simplement à l'unique adresse IP configurÊe. Par consÊquent, la cible MASQUERADE permet de faire fonctionner un système d'adressage IP dynamique sous DHCP, que votre FAI devrait vous procurer pour des connexions à Internet de type PPP, PPPoE ou SLIP.
7-4. 6.4. La table Raw▲
La table Raw est principalement utilisÊe pour placer des marques sur les paquets qui ne doivent pas être vÊrifiÊs par le système de traçage de connexion. Ceci est effectuÊ en utilisant la cible NOTRACK sur le paquet. Si une connexion rencontre une cible NOTRACK, conntrack ne tracera pas cette connexion. Ceci Êtait impossible à rÊsoudre sans l'ajout d'une nouvelle table, car aucune des autres tables n'est appelÊe jusqu'à ce que conntrack ait ÊtÊ lancÊ sur les paquets, et ait ÊtÊ ajoutÊ aux tables conntrack, ou vÊrifiÊ sur une connexion existante. à ce sujet, voir le chapitre La machine d'ÊtatLa machine d'Êtat.
Cette table ne supporte que les chaÎnes PREROUTING et OUTPUT. Aucune autre chaÎne n'est nÊcessaire, car c'est le seul endroit oÚ vous pouvez opÊrer sur les paquets avant qu'ils soient vÊrifiÊs par le traçage de connexion.
Pour que cette table fonctionne, le module iptable_raw doit ĂŞtre chargĂŠ. Il sera chargĂŠ automatiquement si iptables est lancĂŠ avec l'option -t raw, et si le module est disponible.
7-5. La table Filter▲
La table filter sert principalement à filtrer les paquets. On peut Êtablir une correspondance avec des paquets et les filtrer comme on le dÊsire. C'est l'endroit prÊvu pour intervenir sur les paquets et analyser leur contenu, c'est-à -dire les dÊtruire (avec la cible DROP) ou les accepter (avec ACCEPT) suivant leur contenu. Bien entendu, il est possible de rÊaliser prÊalablement du filtrage ; malgrÊ tout, cette table a ÊtÊ spÊcialement conçue pour ça. Presque toutes les cibles sont utilisables dans celle-ci. D'autres informations seront donnÊes sur la table filter, cependant vous savez maintenant que c'est l'emplacement idÊal pour effectuer votre filtrage principal.
7-6. ChaĂŽnes utilisateurs spĂŠcifiques▲
Si un paquet pÊnètre dans une chaÎne comme la chaÎne INPUT de la table Filter, vous pouvez spÊcifier une règle (saut) vers une chaÎne diffÊrente dans la même table. La nouvelle chaÎne doit être spÊcifique utilisateur, elle ne peut pas être gÊnÊrique comme les chaÎnes INPUT et FORWARD par exemple. Si nous considÊrons un pointeur vers une règle d'une chaÎne à exÊcuter, ce pointeur passera de règle en règle, du sommet à la base, jusqu'à ce que la traversÊe de la chaÎne soit close par une cible ou la même chaÎne (i.e. FORWARD, INPUT, etc.). Une fois ceci fait, la stratÊgie par dÊfaut de la chaÎne gÊnÊrique sera appliquÊe.
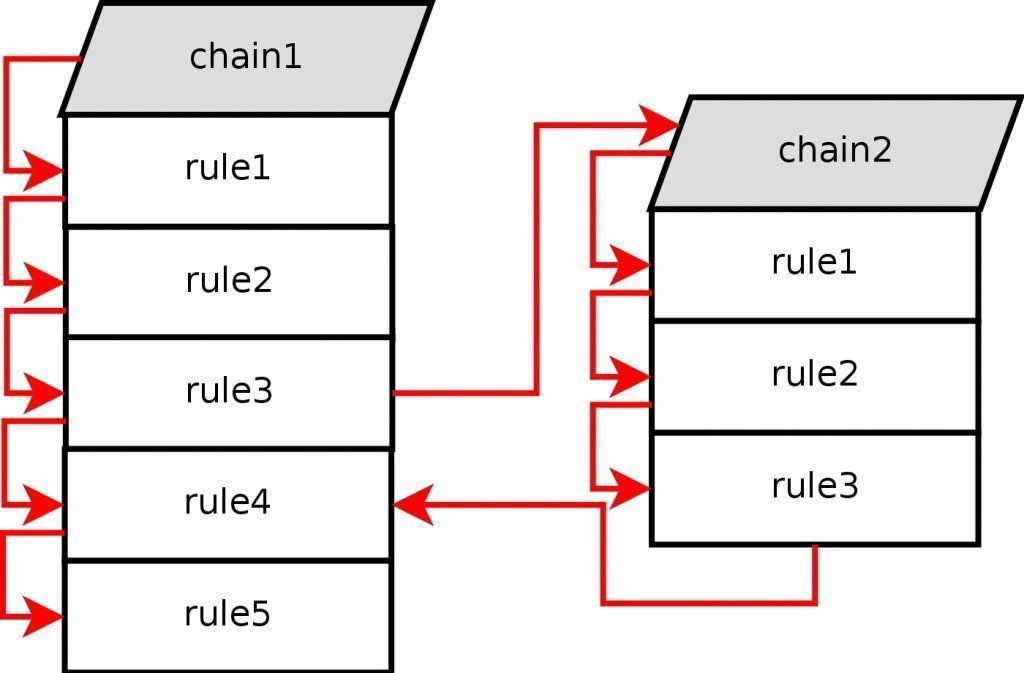
Si une des ces chaÎnes pointe vers une autre chaÎne spÊcifique utilisateur, le pointeur sautera cette chaÎne et dÊmarrera la traversÊe des chaÎnes depuis le sommet jusqu'à la base. Par exemple, voir comment la règle saute de l'Êtape 3 vers la chaÎne 2 dans l'image ci-dessus. Le paquet sÊlectionne les correspondances contenues dans la règle 3, et cible/saute vers la chaÎne 2.
Les chaÎnes spÊcifiques utilisateur ne peuvent pas avoir de stratÊgie par dÊfaut. Seules les chaÎnes gÊnÊriques le peuvent. Ceci peut être contournÊ en ajoutant une simple règle à la fin de la chaÎne, ainsi elle aura une stratÊgie par dÊfaut. Si aucune règle n'est sÊlectionnÊe dans une chaÎne spÊcifique utilisateur, le comportement par dÊfaut sera celui de la chaÎne d'origine. Comme vu dans l'image ci-dessus, la règle saute de la chaÎne 2 et retourne vers la chaÎne 1 règle 4.
Chaque règle dans une chaÎne spÊcifique utilisateur est traversÊe jusqu'à ce que, soit une des règles corresponde - alors la cible spÊcifie si la traversÊe se termine ou continue - soit la fin de la chaÎne est atteinte. Si la fin de la chaÎne spÊcifique utilisateur est atteinte, le paquet est envoyÊ en retour vers la chaÎne qui l'invoque. Cette chaÎne peut être, soit une chaÎne spÊcifique utilisateur soit une chaÎne gÊnÊrique.
7-7. Prochain chapitre▲
Dans le prochain chapitre, nous verrons de façon approfondie la machine d'Êtat de Netfilter, et comment les Êtats sont traversÊs et placÊs sur les paquets dans une machine de traçage de connexion.