



I. Copyright et Licence▲
Copyright (c) 2000, 2013 Philippe Latu, Laurent Foucher. Permission is granted to copy, distribute and/or modify this document under the terms of the GNU Free Documentation License, Version 1.3 or any later version published by the Free Software Foundation; with no Invariant Sections, no Front-Cover Texts, and no Back-Cover Texts. A copy of the license is included in the section entitled  GNU Free Documentation License .
Copyright (c) 2000, 2013 Philippe Latu, Laurent Foucher. Permission est accordÊe de copier, distribuer et/ou modifier ce document selon les termes de la Licence de Documentation Libre GNU (GNU Free Documentation License), version 1.3 ou toute version ultÊrieure publiÊe par la Free Software Foundation ; sans Sections Invariables ; sans Texte de Première de Couverture, et sans Texte de Quatrième de Couverture. Une copie de la prÊsente Licence est incluse dans la section intitulÊe  Licence de Documentation Libre GNU .
I-A. MĂŠtainformation▲
Cet article est Êcrit avec DocBook XML sur un système Debian GNU/Linux. Il est disponible en version imprimable au format PDF : linux.networking.pdf.
I-B. Conventions typographiques▲
Tous les exemples d'exÊcution des commandes sont prÊcÊdÊs d'une invite utilisateur ou prompt spÊcifique au niveau des droits utilisateurs nÊcessaires sur le système.
- Toute commande prÊcÊdÊe de l'invite $ ne nÊcessite aucun privilège particulier et peut être utilisÊe au niveau utilisateur simple.
- Toute commande prÊcÊdÊe de l'invite # nÊcessite les privilèges du super-utilisateur.
II. PrĂŠsentation du noyau LINUX▲
II-A. Introduction▲
Linux s'intègre dans la longue histoire des systèmes UNIX. Le dÊveloppement de ce système d'exploitation a dÊbutÊ en 1969 sous l'impulsion de Ken Thompson et Dennis Ritchie qui travaillaient alors pour la sociÊtÊ Bell Laboratories. Plusieurs versions furent dÊveloppÊes en interne et c'est en 1975 qu'apparut la version 6 qui deviendra la base des UNIX commerciaux.
Par la suite, de nombreuses implĂŠmentations d'UNIX furent dĂŠveloppĂŠes. L'universitĂŠ de Berkeley fut Ă la base de la version BSD, Hewlett Packard proposa la version HP-UX, etc. MalgrĂŠ de bonnes intentions au dĂŠpart, il existait des incompatibilitĂŠs entre tous ces UNIX, si bien que le portage d'une application d'un UNIX vers un autre ĂŠtait difficile. Pour rĂŠduire ces disparitĂŠs, la sociĂŠtĂŠ AT&T proposa un standard UNIX en 1983, connu sous le nom de System V. En 1986, l'Institute of Electrical and Electronics Engineers (IEEE) proposa un autre standard connu sous le terme de POSIX. POSIX est une standardisation permettant d'assurer la portabilitĂŠ des applications d'un UNIX Ă un autre.
Le système d'exploitation GNU/Linux se comporte comme un UNIX et implÊmente les spÊcifications POSIX, avec des extensions système V et BSD.
Issu du travail d'un Êtudiant finlandais, Linus Torvalds, Linux se distingue par le fait qu'il est distribuÊ sous les conditions d'une licence particulière, appelÊe GPL (GNU Public License). Cette licence prÊcise que toute personne peut modifier, amÊliorer ou corriger le code source, mais que ces modifications devront Êgalement être distribuÊes librement.
Les principales caractÊristiques de Linux sont les suivantes :
- Multitâche : exÊcute plusieurs programmes en même temps ;
- Multiutilisateur : plusieurs utilisateurs peuvent être actifs en même temps ;
- Multiplateforme : Linux peut fonctionner avec diffÊrents types de processeurs (Intel, Sparc, Alpha, PowerPC, etc.) ;
- Supporte un grand nombre de systèmes de fichiers : Ext(2|3|4), XFS, FAT, VFAT, NFS, CIFS, etc. ;
- Dispose d'un catalogue de fonctions rÊseau consÊquent. Voir Section 3,  Sous-système rÊseau du noyau LINUX .
L'Êvolution du noyau est très rapide et celui qui est utilisÊ pour ce programme de formation appartient à la sÊrie 2.6.
II-B. Architecture du système GNU/Linux▲
Comme dans tout système d'exploitation, le noyau LINUX est une interface entre des programmes et des pÊriphÊriques physiques. L'accès à ces pÊriphÊriques se fait par l'intermÊdiaire d'appels système qui sont identiques quelle que soit la machine. Cette encapsulation du matÊriel libère les dÊveloppeurs de logiciels de la gestion complexe des pÊriphÊriques : c'est le système d'exploitation qui s'en charge. Ainsi, si le système d'exploitation existe sur plusieurs architectures, l'interface d'utilisation et de programmation sera la même sur toutes. On dira alors que le système d'exploitation offre une machine virtuelle à l'utilisateur et aux programmes qu'il exÊcute.
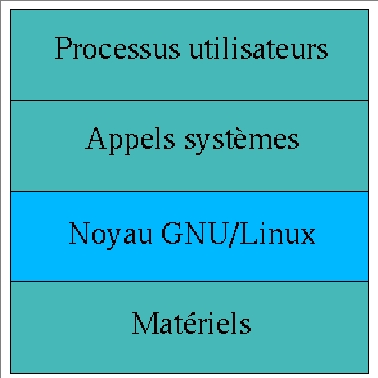
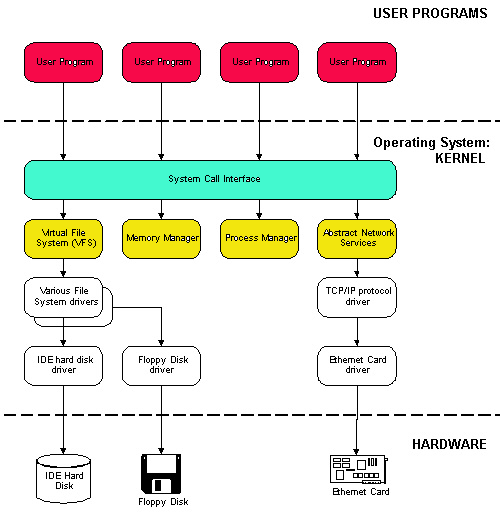
GNU/Linux est considÊrÊ comme un système d'exploitation monolithique, Êcrit comme un ensemble de procÊdures qui peuvent s'appeler mutuellement. Pour l'utilisateur, il se prÊsente comme un seul gros fichier. Cependant, il contient un ensemble de composants rÊalisant chacun une tâche bien prÊcise. Cette construction monolithique induit un aspect important : la notion d'espace noyau (kernelspace) et d'espace utilisateur (userspace). Dans l'espace noyau, aucune restriction n'est imposÊe. Dans l'espace utilisateur, un certain nombre de restrictions sont imposÊes (par exemple, la crÊation d'un fichier ne peut se rÊaliser que si les droits sont suffisants), et le processus ne peut avoir accès qu'aux zones mÊmoire qui lui ont ÊtÊ allouÊes.
Le noyau LINUX est composÊ de cinq sous-systèmes principaux. Un sous-système peut être dÊfini comme une entitÊ logicielle qui fournit une fonctionnalitÊ particulière.
II-C. Tâches rĂŠalisĂŠes par le noyau LINUX▲
II-C-1. Gestion des processus, Ordonnanceur, Scheduler▲
Ce sous-système est chargÊ de rÊpartir Êquitablement les accès au processeur entre toutes les applications actives. Cela n'inclut pas seulement les processus utilisateurs, mais aussi les sous-systèmes du noyau lui-même. Cette fonction est rÊalisÊe par le Scheduler.
II-C-2. Gestion de la mĂŠmoire▲
Ce sous-système est chargÊ d'affecter à chaque programme une zone mÊmoire. Il a Êgalement un rôle de protection : la mÊmoire pour un processus est privÊe et celle-ci ne doit pas être lue ni modifiÊe par un autre.
II-C-3. Système de fichier virtuel▲
Le sous-système de fichiers garantit une gestion correcte des fichiers et un contrôle des droits d'accès. Pour limiter la complexitÊ liÊe aux nombreux systèmes de fichiers existants, LINUX adopte le concept de Virtual FileSystem (VFS). Le principe du VFS est de proposer des appels système identiques quel que soit le système de fichiers. Il est de la responsabilitÊ du noyau de dÊtourner les appels standards vers les appels spÊcifiques au système de fichiers.
II-C-4. Service rĂŠseau▲
Le sous-système rÊseau permet à Linux de se connecter à d'autres systèmes à travers un rÊseau informatique. Il y a de nombreux pÊriphÊriques matÊriels qui sont supportÊs et plusieurs protocoles rÊseau peuvent être utilisÊs.
II-C-5. Communications Inter Processus▲
Dans la mesure oÚ un processus ne peut avoir accès qu'à la zone mÊmoire qui lui a ÊtÊ allouÊe, LINUX propose plusieurs mÊcanismes permettant à des applications de communiquer entre elles.
Les relations entre les diffĂŠrentes parties du noyau sont montrĂŠes sur la figure ci-dessous.
III. Sous-système rĂŠseau du noyau LINUX▲
III-A. Networking options▲
Le but de cette section est de dĂŠcouvrir les diverses options rĂŠseau que propose le noyau LINUX.
Les fonctions rĂŠseau indĂŠpendantes du matĂŠriel (piles de protocoles, liste de filtres, etc.) sont regroupĂŠes dans les menus Networking puis Networking Options.
Les pilotes de pĂŠriphĂŠriques rĂŠseau sont accessibles Ă partir des menus Device Drivers puis Network device support.
III-B. Packet Socket▲
Cette fonctionnalitĂŠ est utilisĂŠe pour recevoir ou envoyer des paquets bruts sur les pĂŠriphĂŠriques rĂŠseau sans passer par l'intermĂŠdiaire d'un protocole rĂŠseau implĂŠmentĂŠ dans le noyau. Certains programmes, tel que tcpdump, utilisent cette option.
Le terme  socket  dÊsigne l'interface de programmation à travers laquelle l'on va pouvoir accÊder aux ressources rÊseau du noyau. La crÊation d'une interface  socket  est rÊalisÊe par l'appel système suivant :
int fsfuncsocket( famille,
type,
protocole);
int famille;
int type;
int protocole;Le paramètre  famille  permet de prÊciser avec quel protocole rÊseau on souhaite travailler. L'ensemble des familles disponibles est listÊ dans le fichier /usr/include/linux/socket.h. Les types dÊfinissent le protocole de transport (TCP ou UDP). Une nouvelle famille de socket associÊe à cette fonctionnalitÊ est ainsi disponible, à savoir AF_PACKET.
Sous-option de Packet Socket
mapped IOÂ : Cette option permet d'utiliser un mĂŠcanisme d'entrĂŠe-sortie plus rapide.
Exemple 1. Utilisation de la socket packet
#include <stdio.h>
#include <sys/socket.h>
#include <sys/ioctl.h>
#include <net/if.h>
#include <linux/if_ether.h>
#include <linux/if_packet.h>
main ()
{
int sock_fd ;
struct sockaddr_ll sll;
struct ifreq ifr;
char buffer[2000];
int nb_octet;
if (sock_fd = socket(AF_PACKET,SOCK_RAW,htons(ETH_P_ALL)) == -1 ) {
printf("Erreur dans la crĂŠation de la socket\n");
return-1 ;
}
memset(&ifr, 0, sizeof(ifr));
strncpy (ifr.ifr_name, "eth0", sizeof(ifr.ifr_name));
if (ioctl(sock_fd,SIOCGIFINDEX, &ifr) == -1 ) {
printf("Erreur dans la recherche de index\n");
return -1 ;
}
memset(&sll, 0, sizeof(sll));
sll.sll_family = AF_PACKET ;
sll.sll_ifindex = ifr.ifr_ifindex ;
sll.sll_protocol = htons(ETH_P_ALL);
if (bind(sock_fd, (struct sockaddr *) &sll, sizeof(sll)) == -1) {
printf("Erreur avec bind\n");
return -1 ;
};
nb_octet=recvfrom(sock_fd,buffer,sizeof(buffer),0,NULL,0);
printf("Nombre d'octets reçus : %d\n",nb_octet);
}III-C. Kernel/User netlink socket▲
Kernel/User netlink socket : DÊfinit une nouvelle famille de socket, AF_NETLINK. Cette socket permet d'Êtablir une communication bidirectionnelle entre le noyau et l'espace utilisateur. Cette option est nÊcessaire pour pouvoir utiliser l'outil iproute2 qui permet la configuration de la partie rÊseau du noyau.
En plus de cette socket, la communication peut Êgalement se rÊaliser, pour un processus utilisateur, par la lecture ou l'Êcriture de fichiers caractères spÊciaux. Ces fichiers spÊciaux ont le numÊro majeur 36 et se trouvent dans le rÊpertoire /dev.
Sous-option de netlink
Routing Messages : Le noyau fournit des informations sur le routage via le fichier /dev/route de numÊro majeur 36 et de numÊro mineur 0.
Netlink Device Emulation : Permet la compatibilitÊ avec d'anciennes fonctionnalitÊs. Option amenÊe à disparaÎtre.
III-D. Socket Filtering▲
Cette fonctionnalitĂŠ permet, dans les programmes en mode utilisateur, la mise en place de filtres au niveau des sockets. On a ainsi la possibilitĂŠ d'autoriser ou d'interdire des types de donnĂŠes traversant une socket. Cette fonctionnalitĂŠ est dĂŠrivĂŠe du filtrage de paquets Berkeley. Pour plus d'informations, voir le fichier Documentation/networking/filter.txt dans les sources du noyau.
III-E. UNIX domain socket▲
Permet la prise en charge des sockets du domaine UNIX. X-windows et syslog sont des exemples de programmes qui utilisent ce type de fonctionnalitĂŠ. Les sockets UNIX ne permettent que des communications locales sur une machine. Ce type de socket est liĂŠ Ă la crĂŠation d'un fichier. Le nom de la famille associĂŠ aux sockets du domaine UNIX est AF_UNIX.
Exemple 2. Utilisation de la socket UNIX
#include <stdio.h>
#include <stdlib.h>
#include <errno.h>
#include <string.h>
#include <sys/types.h>
#include <sys/socket.h>
#include <sys/un.h>
int main(void)
{
int socket_unix, len;
struct sockaddr_un local;
if ((socket_unix = socket(AF_UNIX, SOCK_STREAM, 0)) == -1) {
perror("socket");
exit(1);
}
local.sun_family = AF_UNIX;
strcpy(local.sun_path,"/tmp/test_socket_unix");
unlink(local.sun_path);
len = strlen(local.sun_path) + sizeof(local.sun_family);
if (bind(socket_unix, (struct sockaddr *)&local, len) == -1) {
perror("bind");
exit(1);
}
system("ls -l /tmp/");
unlink(local.sun_path);
return 0;
}III-F. TCP/IP networking▲
Active le protocole TCP/IP.
III-F-1. IPÂ : multicasting▲
Permet d'envoyer des paquets Ă plusieurs ordinateurs en mĂŞme temps. Cette fonctionnalitĂŠ est, par exemple, utilisĂŠe pour la diffusion audio et vidĂŠo.
III-F-2. IPÂ : advanced router▲
Par dÊfaut, la dÊcision du routage se fait en examinant l'adresse de destination. En activant cette option, on peut contrôler beaucoup plus prÊcisÊment le routage et la prise de dÊcision pourra se faire en fonction de nombreux autres critères.
Sous-option de advanced router
policy routing : Permet le remplacement de la table de routage classique, basÊe sur les adresses de destination, par la Base de DonnÊes des Politiques de Routage ou Routing Policy DataBase (RPDB) en anglais. Cette base de donnÊes est une liste ordonnÊe de règles qui scrutent certaines caractÊristiques des paquets :
- adresse source ;
- adresse de destination ;
- champ TOSÂ ;
- marque du paquet ;
- interface d'entrĂŠe.
Si un paquet satisfait les spÊcifications d'une règle, alors l'action correspondante est rÊalisÊe. L'action standard consiste à fournir l'adresse IP du prochain saut. Si vous souhaitez plus d'informations sur ce sujet, je vous conseille la lecture de deux documents :
- La documentation ip-cref d'Alexey Kuznetsov, disponible avec le paquet iproute.
- L'article Policy Routing for Fun and Profit.
- L'article Policy Routing in Linux.
De plus, un exemple complet de routage avancĂŠ peut ĂŞtre consultĂŠ dans le document LARTCÂ : bases de donnĂŠes des politiques de routage.
Si l'option IP: use netfilter MARK value as routing key est validĂŠe, le routage des paquets pourra s'ĂŠtablir en fonction de la marque du paquet. Un exemple peut ĂŞtre consultĂŠ dans le document LARTCÂ : Netfilter et iproute - marquage de paquets.
Si l'option IP: fast network translation address est validĂŠe, le routeur pourra modifier les adresses source et destination des paquets transmis.
Exemple 3. Exemple de NAT
Soit un routeur avec d'un cĂ´tĂŠ un rĂŠseau local 192.168.1.0/24 et de l'autre un rĂŠseau public (200.200.200.0/24, par exemple) ayant une connectivitĂŠ sur Internet. On souhaite qu'une machine du rĂŠseau local (192.168.1.1, par exemple) soit reconnue avec l'adresse 200.200.200.10 sur Internet.
$ ip route add nat 200.200.200.10 via 192.168.1.1
$ ip rule add prio 300 from 192.168.1.1 nat 200.200.200.10equal cost multipath : Avec cette option, on peut spÊcifier plusieurs routes alternatives que peuvent emprunter les paquets. Le routeur considère toutes ces routes comme Êtant de coÝts Êgaux et choisit l'une d'elles d'une manière non dÊterministe si un paquet arrive avec la bonne correspondance.
Exemple 4. Exemple de chemins multiples
ConsidĂŠrons un routeur avec deux liaisons PPP. On souhaite que les paquets sortants puissent utiliser indiffĂŠremment ppp0 ou ppp1 comme interface de route par dĂŠfaut.
$ ip route add default scope global nexthop dev ppp0 nexthop dev ppp1use TOS value as routing key : L'entête d'un paquet IP contient un champ de 8 bits nommÊ Type Of Service (Type de service). Dans ce champ, il y a trois indicateurs qui permettent de prÊciser le type d'acheminement souhaitÊ : DÊlai faible (faible temps d'attente), dÊbit important et fiabilitÊ importante. Cela permet de choisir entre, par exemple, une liaison satellite à haut dÊbit, mais avec un dÊlai d'attente important ou une ligne louÊe à faible dÊbit et faible dÊlai. Cette option permet d'utiliser la valeur du champ TOS dans la liste de règles.
Exemple 5. Exemple d'utilisation du champ TOS pour le routage
But : Tous les paquets marquÊs avec le champ TOS dÊbit important (0x08) (par exemple le transfert de donnÊes via FTP) doivent emprunter une liaison RNIS.
$ip rule add tos 0x08 prio 100 table 10
$ip route add default dev ippp0 table 10verbose route monitoring : Permet l'affichage de messages au sujet du routage.
large routing tables : Si la table de routage possède plus de 64 entrÊes, il est prÊfÊrable d'activer cette option pour accÊlÊrer le processus de routage.
III-F-3. IPÂ : kernel level autoconfiguration▲
Cette option permet de configurer les adresses IP des pĂŠriphĂŠriques au moment du dĂŠmarrage, ainsi que la table de routage. Les informations nĂŠcessaires Ă cette configuration sont fournies soit sur la ligne de commande, soit par l'intermĂŠdiaire des protocoles DHCP, BOOTP ou RARP.
Les informations sont fournies au noyau via le paramètre ip. Cette option est principalement utilisÊe pour la mise en place de stations clientes sans disque dur et qui ont besoin de monter la racine du système de fichiers via NFS. Pour plus d'informations, voir le fichier Documentation/nfsroot.txt dans les sources du noyau.
Exemple 6. Exemple de configuration IP au dÊmarrage
LILO: linux ip=192.168.1.1::192.168.1.254:255.255.255.0:Linuxbox:eth0:noneIII-F-4. IPÂ : optimize as router not host▲
Permet de supprimer certaines vÊrifications lorsque le noyau reçoit un paquet. Dans le cas oÚ Linux est principalement utilisÊ comme un routeur, c'est-à -dire une machine qui ne fait que transmettre les paquets, cela permet d'amÊliorer la vitesse de commutation.
III-F-5. IPÂ : tunneling▲
Le tunneling permet l'encapsulation d'un protocole rĂŠseau dans un autre protocole rĂŠseau. Cette option permet l'encapsulation du protocole IP dans IP. Cela peut ĂŞtre utilisĂŠ dans le cas oĂš l'on souhaite pouvoir faire communiquer deux rĂŠseaux ayant des adresses privĂŠes, donc non routables, Ă travers l'Internet. Un exemple complet de tunnel IP dans IP pourra ĂŞtre consultĂŠ dans le document LARTCÂ : IP dans un tunnel IP.
III-F-6. IPÂ : GRE tunnel over IP▲
GRE est un protocole de tunnel qui a ĂŠtĂŠ originellement dĂŠveloppĂŠ par CISCOâ˘, et qui peut rĂŠaliser plus de choses que le tunnel IP dans IP. Par exemple, on peut aussi transporter du trafic multidiffusion et de l'IPv6 Ă travers un tunnel GRE. Un exemple complet de tunnel GRE pourra ĂŞtre consultĂŠ dans le document LARTC : Le tunnel GRE.
III-F-7. IPÂ : TCP Explicit Congestion Notification support▲
FonctionnalitĂŠ qui permet aux routeurs d'annoncer aux clients une congestion du rĂŠseau.
III-F-8. IPÂ : TCP syncookie support▲
PrĂŠvient une attaque appelĂŠe le SYN Flooding.
III-F-9. IPÂ : Allow large windows (not recommanded if <16 Mb of memory)▲
Permet de dĂŠfinir de plus gros tampons dans lesquels les donnĂŠes sont stockĂŠes avant d'ĂŞtre envoyĂŠes Ă l'hĂ´te destinataire.
III-F-10. Network packet filtering (remplace ipchains)▲
Cette option active la fonction de filtrage des paquets traversant la machine Linux. Le filtrage permet un blocage sĂŠlectif du trafic IP en fonction, par exemple, de l'origine ou de la destination.
Sous-option de Network packet filtering
Network packet filtering debugging : Permet d'avoir des messages supplÊmentaires du code netfilter.
Bridge IP/ARP packet filtering : Permet d'utiliser les fonctionnalitÊs de filtrage netfilter lorsque la machine est configurÊe pour fonctionner comme un pont.
III-F-11. IPÂ : Netfilter configuration▲
Permet de rentrer dans un nouveau menu pour la configuration du filtrage. Celui-ci permet l'ajout de fonctionnalitÊs dont voici une liste des plus importantes :
Sous-option de Netfilter configuration
Connection tracking (required for masq/NAT)Â : Cette option permet de mettre en place le filtrage dit StateFul. Cette technique permet de garder en mĂŠmoire, dans une table d'ĂŠtat, une trace des ÂŤcommunications en coursÂť. Cela permet de diffĂŠrencier le trafic entre les hĂ´tes pairs, en ĂŠmission et en rĂŠception. Cette option est indispensable pour l'utilisation des mĂŠcanismes de traduction d'adresse.
Connection mark tracking support : Cette option permet d'activer le support du marquage des communications. Ce support est nÊcessaire pour le critère de sÊlection connmark (voir connection mark match support) et pour la cible CONNMARK (voir Packet Mangling).
IP tables support (required for filtering/masq/NAT)Â : Cette option permet la mise en place de la structure gĂŠnĂŠrale pour le filtrage, le masquage ou la traduction d'adresse des paquets.
III-F-11-a. limit match support▲
Permet de limiter le dÊbit en fonction d'une règle de correspondance.
# iptables -A INPUT -p icmp -icmp-type echo-request -m limit --limit 1/second -j ACCEPTIII-F-11-b. IP range match support▲
Permet de spĂŠcifier un intervalle d'adresses source ou destination.
# iptables -A FORWARD -m iprange --src-range 192.168.1.1-192.168.1.10 -j ACCEPT# iptables -A FORWARD -m iprange --dst-range 192.168.1.1-192.168.1.10 -j ACCEPTIII-F-11-c. MAC address match support▲
Permet de baser le filtrage sur les adresses MAC des trames Ethernet.
# iptables -A INPUT -m mac --mac-source 00:A0:24:A0:A4:11 -j DROPIII-F-11-d. Packet type match support▲
Permet de considÊrer le type de paquet : unicast, broadcast ou multicast.
# iptables -A INPUT -m pkttype --pkt-type broadcast -j LOGIII-F-11-e. netfilter MARK match support▲
Permet de baser le filtrage sur la marque d'un paquet. Le marquage d'un paquet est rÊalisÊ grâce à la cible MARK.
# iptables -A PREROUTING -t mangle -p tcp --dport 80 -j MARK --set-mark=2
# iptables -A INPUT -m mark --mark 2 -j DROPIII-F-11-f. multiple port match support▲
Permet de spĂŠcifier un ensemble de ports sources ou destinations TCP ou UDP.
# iptables -A INPUT -p tcp -m multiport --source-ports 3000,4000 -j DROPIII-F-11-g. TOS match support▲
Permet de baser le filtrage sur la valeur du champ TOS du paquet.
# iptables -t mangle -A PREROUTING -m tos --tos Minimize-Delay -j MARK --set-mark=1III-F-11-h. recent match support▲
Permet de baser le filtrage en recherchant la prĂŠsence d'une adresse dans une liste.
# iptables -A FORWARD -m recent --rcheck --seconds 60 -j DROP
# iptables -A FORWARD -i eth0 -d 127.0.0.0/8 -m recent --set -j DROPIII-F-11-i. ECN match support▲
La RFC3168 dĂŠfinit un mĂŠcanisme de notification de congestion. Ce mĂŠcanisme utilise les bits 7 et 8 du champ Type Of Service et l'en-tĂŞte IPv4 et dĂŠfinit deux nouveaux flags dans l'en-tĂŞte TCP. Ces flags ont pour noms CWR pour Congestion Window Reduced et ECE pour ECN-Echo.
III-F-11-j. DSCP match support▲
Permet de baser le filtrage sur la valeur des 6 bits DSCP de l'en-tĂŞte IP.
# iptables -t mangle -A FORWARD -p tcp --dport 80 -j DSCP --set-dscp-class EF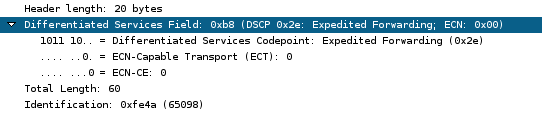
III-F-11-k. AH/ESP match support▲
Ă complĂŠter
III-F-11-l. LENGTH match support▲
Permet de baser le filtrage sur la longueur, exprimĂŠe en octets, du paquet IP.
# iptables -A FORWARD -p icmp --icmp-type echo-request -m length --length ! :84 -j DROPIII-F-11-m. TTL match support▲
Permet de baser le filtrage sur la valeur du champ TTL Time To Live de l'en-tĂŞte du paquet IP.
III-F-11-n. tcpmss match support▲
Permet de baser le filtrage sur la valeur de l'option MSS Maximum Segment Size du protocole de transport TCP.
# iptables -A OUTPUT -o ppp0 -p tcp -m tcpmss --mss 0:1400 -j ACCEPTIII-F-11-o. Helper match support▲
Ă complĂŠter
III-F-11-p. Connection state match support▲
Permet de baser le filtrage sur l'ĂŠtat des ÂŤcommunicationsÂť.
# iptables -P INPUT DROP
# iptables -A INPUT -i eth0 -m conntrack --ctstate NEW,INVALID -j DROP
# iptables -A INPUT -i eth0 -m conntrack --ctstate ESTABLISHED,RELATED -j ACCEPTIII-F-11-q. Connection tracking match support▲
Permet d'activer le module de critère de sÊlection conntrack. Cette option permet une plus grande granularitÊ de recherche dans le suivi de communication.
# iptables -A FORWARD -m conntrack --ctstate ESTABLISHED,RELATED --ctproto tcp -j ACCEPTIII-F-11-r. Owner match support▲
Permet de baser le filtrage sur l'identifiant du processus local ayant crĂŠĂŠ le paquet. Cette option ne peut ĂŞtre utilisĂŠe que dans la chaĂŽne OUTPUT.
III-F-11-s. Physdev match support▲
Dans le cas oĂš la machine est configurĂŠe comme un pont entre deux rĂŠseaux Ethernet, cette option permet de repĂŠrer l'interface physique sur laquelle arrivent les paquets ou sur laquelle ils doivent partir.
# iptables -A FORWARD -m physdev --physdev-out eth0 -j LOG --log-level 7III-F-11-t. address type match support▲
Permet de baser le filtrage en fonction de la nature de l'adresse.
# iptables -A INPUT -m addrtype --dst-type MULTICAST -j ACCEPTIII-F-11-u. realm match support▲
Ă complĂŠter
III-F-11-v. SCTP protocol match support▲
Ă complĂŠter
III-F-11-w. comment match support▲
Ă complĂŠter
III-F-11-x. connection mark match support▲
Permet d'activer le critère de recherche connmark. Ce critère permet de repÊrer la marque associÊe à une communication.
# iptables -A OUTPUT -o eth0 -m connmark --mark 1 -j ACCEPTIII-F-11-y. hashlimit match support▲
Ă complĂŠter
III-F-11-z. Packet filtering▲
Cette option permet le support du filtrage de paquets. La table gÊrant le filtrage se nomme filter et possède les chaÎnes par dÊfaut INPUT, FORWARD et OUTPUT. La sous option REJECT target support ajoutera la cible REJECT. Cette cible permet de renvoyer un paquet d'erreurs à la machine Êmettrice, simulant ainsi l'absence d'un service.
# iptables -A INPUT -p tcp -s 192.168.0.0/24 --dport 22 \
-j REJECT --reject-with tcp-resetIII-F-11-aa. LOG target support▲
Cette option permet l'enregistrement des paquets grâce au dÊmon syslogd.
# iptables -A OUTPUT -p tcp --dport 80 \
-j LOG --log-level 7 --log-prefix "Paquets WEB :"III-F-11-ab. ULOG target support▲
Permet d'activer la cible ULOG utilisĂŠe pour envoyer Ă travers une socket netlink le paquet Ă un processus de l'espace utilisateur Ă des fins d'enregistrement.
III-F-11-ac. TCPMSS target support▲
Permet de modifier la valeur du champ MSS contenu dans l'en-tête TCP grâce à la cible TCPMSS. L'usage le plus courant de cette règle de correspondance vise à adapter la taille maximale des segments TCP à la taille maximale des unitÊs transmises au niveau rÊseau : MTU ou Maximum Transmit Unit.
# iptables -A POSTROUTING -o ppp0 -p tcp -m tcpmss --mss 1400:1536 \
-j TCPMSS --clamp-mss-to-pmtuIII-F-11-ad. Full NAT▲
Cette option permet le support de la traduction des adresses source (SNAT) et destination (DNAT).
- La sous option MASQUERADE target support permet l'utilisation du masquerading comme traducteur d'adresse source.
- La sous option REDIRECT target support permet la redirection des paquets vers la machine locale. Cette cible est utilisĂŠe dans la mise en place de proxies transparents.
- La sous option NETMAP target support permet d'activer le cible NETMAP. Cette cible permet de rediriger le trafic destinĂŠ aux hĂ´tes d'un rĂŠseau vers les hĂ´tes d'un autre rĂŠseau.
- La sous option SAME target support permet d'activer la cible SAME. Cette cible permet de traiter le cas particulier d'une traduction d'adresse source oĂš plusieurs adresses de traduction peuvent ĂŞtre utilisĂŠes. Avec cette cible, on s'assure que la mĂŞme adresse source sera utilisĂŠe pour tous les paquets d'une mĂŞme communication.
# iptables -t nat -A POSTROUTING -o eth0 -j SNAT --to 200.200.200.1# iptables -t nat -A PREROUTING -p tcp --dport 80 -j DNAT --to 200.200.200.1:8080III-F-11-ae. Packet Mangling▲
Cette option permet de modifier certains ĂŠlĂŠments du paquet.
- La sous option TOS target support permet de modifier le champ TOS du paquet.
- La sous option ECN target support permet de supprimer les bits ECN.
- La sous option MARK target support permet de marquer les paquets. Ces marques pourront ĂŞtre utilisĂŠes par la suite pour, par exemple, imposer un routage particulier ou par l'outil de configuration de la qualitĂŠ de service tc.
- La sous option CLASSIFY target support permet de positionner des paquets dans des classes de qualitĂŠ de service.
- La sous option TTL target support permet de modifier la valeur du champ TTL dans l'en-tĂŞte IP.
- La sous option CONNMARK target support permet de marquer les paquets appartenant Ă une communication. Ces marques pourront ĂŞtre utilisĂŠes par la suite pour, par exemple, imposer un routage particulier.
# iptables -A PREROUTING -t mangle -p tcp --dport Telnet -j TOS --set-tos Minimize-Delay# iptables -A PREROUTING -p tcp --dport 33434:33542 -j TTL --ttl-inc 1# iptables -A POSTROUTING -t mangle -j CONNMARK --restore-mark # remark 1
# iptables -A POSTROUTING -t mangle -m mark ! --mark 0 -j ACCEPT # remark 2
# iptables -A POSTROUTING -t mangle -p tcp --dport 21 -j MARK --set-mark 1 # remark 3
# iptables -A POSTROUTING -t mangle -j CONNMARK --save-mark # remark 4|
1 |
Permet d'imposer aux paquets appartenant Ă une connexion la marque dĂŠfinie pour le premier paquet de cette connexion. |
|
2 |
Si le paquet possède dÊjà une marque, celui-ci est acceptÊ, car cela signifie que ce n'est pas le premier paquet d'une connexion. |
|
3 |
Le premier paquet d'une nouvelle connexion FTP est marquĂŠ avec la marque 1. |
|
4 |
La marque du premier paquet sera considÊrÊe comme Êtant la marque de tous les paquets de la connexion. Cette marque sera imposÊe aux autres paquets associÊs à la connexion grâce à la première règle. |
III-G. 802.1Q VLAN Support▲
De nos jours, les rĂŠseaux locaux ou LAN (Local Area Network) sont dĂŠfinis comme ĂŠtant un domaine de diffusion unique. Les rĂŠseaux locaux virtuels ou VLAN permettent de dĂŠfinir des rĂŠseaux locaux logiques sans se soucier de la localisation physique du matĂŠriel. Ces VLAN sont identifiĂŠs par une balise. Suivant la configuration du commutateur, il est parfois nĂŠcessaire d'indiquer Ă quel VLAN appartient une trame qui est envoyĂŠe sur le rĂŠseau. C'est ici que le protocole IEEE 802.1Q intervient. Ce protocole va permettre le marquage des trames Ethernet.
LinuxBox# modprobe 8021q
LinuxBox# ifconfig eth0 0.0.0.0 up
LinuxBox# vconfig add eth0 2
LinuxBox# ifconfig eth0.2 192.168.1.1 upLa figure ci-dessous propose un exemple de trame Ethernet avec le support du protocole IEEE 802.1Q.
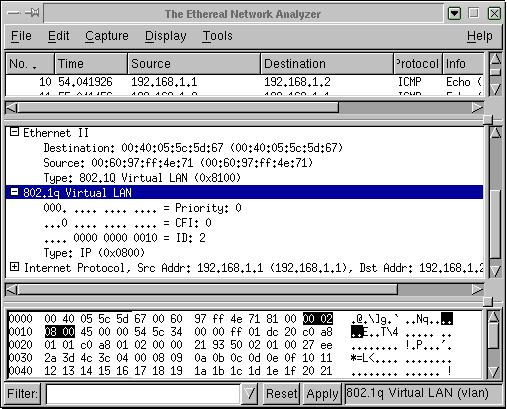
Le document Routage InterVLAN dĂŠveloppe beaucoup plus en dĂŠtail l'utilisation des VLAN sur GNU/Linux.
III-H. Le protocole IPX▲
Ajoute le support du protocole IPX, principalement utilisĂŠ par les rĂŠseaux Novellâ˘. IPX est un protocole de couche 3 (couche rĂŠseau).
III-I. Appletalk DDP▲
Appletalk est le protocole de communication des ordinateurs Appleâ˘. Cette option permet Ă la machine Linux de pouvoir dialoguer avec les machines Appleâ˘. En utilisant le programme netatalk, Linux peut agir comme serveur d'impression et de fichiers pour Mac. Il pourra ĂŠgalement accĂŠder aux imprimantes Appletalk.
III-J. DECnet support▲
La sociÊtÊ Digital Equipment Corporation⢠a crÊÊ une architecture rÊseau complète qui porte le nom de DNA (Digital Network Architecture). Cette architecture s'appuie sur une pile de protocole qui englobe l'ensemble des couches du modèle OSI. Les produits qui implÊmentent l'architecture DNA sont appelÊs produits DECNet. Par abus de langage, on utilise parfois le terme DECNet pour identifier un rÊseau DNA.
Pour plus d'informations sur ce sujet, consulter le site officiel du support DECnet for Linux.
III-K. 802.1d Ethernet Bridging▲
Avec cette option, votre boÎte Linux pourra être assimilÊe à un pont Ethernet ; ce qui signifie que les diffÊrents segments Ethernet connectÊs apparaÎtront comme un seul rÊseau Ethernet. Plusieurs ponts de ce type peuvent fonctionner ensemble pour crÊer un rÊseau de segments Ethernet encore plus grand en utilisant l'algorithme de Spanning Tree Protocol (IEEE 802.1d). Comme le protocole IEEE 802.1d est un standard universel, les ponts Linux fonctionneront correctement avec des Êquipements tiers.
Pour utiliser un pont Ethernet, vous aurez besoin des outils de configuration de pont. Voir Documentation/networking/bridge.txt pour plus d'information. Lire aussi le Linux BRIDGE-STP-HOWTO.
Notez que si votre machine fonctionne en pont, elle contient plusieurs interfaces Ethernet. Le noyau n'est pas capable de reconnaĂŽtre plus d'une interface au dĂŠmarrage sans assistance. Pour plus de dĂŠtails, lire le document Technologie Ethernet.
IV. Les outils rĂŠseau du noyau Linux▲
Le code des outils de configuration rĂŠseau ne faisant pas partie du noyau est gĂŠnĂŠralement appelĂŠÂ : userspace code.
IV-A. Configuration des interfaces rĂŠseau▲
Ă partir de la version 2.2 du noyau LINUX, de nombreuses fonctionnalitĂŠs sont apparues dans le support du protocole TCP/IP, notamment au niveau du routage. Pour pouvoir utiliser ces nouveautĂŠs, les outils classiques tels que ifconfig ou route ne suffisent plus. Il convient d'utiliser un nouvel outil, appelĂŠ iproute2. Le paquet de la distribution Debian GNU/Linux est baptisĂŠ iproute.
La syntaxe gÊnÊrale pour l'outil iproute2 est la suivante :
Usage: ip [ OPTIONS ] OBJET { COMMAND | help }
oĂš OBJET := { link | addr | route | rule | neigh | tunnel |
maddr | mroute | monitor }
OPTIONS := { -V[ersion] | -s[tatistics] | -r[esolve] |
-f[amily] { inet | inet6 | dnet | link } | -o[neline] }Les diffĂŠrents objets permettent de voir ou de configurer un ĂŠlĂŠment du rĂŠseau.
IV-B. ip link▲
L'objet link permet de visualiser l'Êtat des pÊriphÊriques rÊseau et de les modifier. La syntaxe gÊnÊrale pour cette option est la suivante :
Usage: ip link set DEVICE { up | down | arp { on | off } |
dynamic { on | off } |
multicast { on | off } | txqueuelen PACKETS |
name NEWNAME |
address LLADDR | broadcast LLADDR |
mtu MTU }
ip link show [ DEVICE ]Cette option ne s'intÊresse qu'au niveau 2 du modèle OSI.
IV-C. ip address▲
Cet objet permet d'attacher une ou plusieurs adresses IPv4 ou IPv6 Ă un pĂŠriphĂŠrique rĂŠseau.
Usage: ip addr {add|del} IFADDR dev STRING
ip addr {show|flush} [ dev STRING ] [ scope SCOPE-ID ]
[ to PREFIX ] [ FLAG-LIST ] [ label PATTERN ]
IFADDR := PREFIX | ADDR peer PREFIX
[ broadcast ADDR ] [ anycast ADDR ]
[ label STRING ] [ scope SCOPE-ID ]
SCOPE-ID := [ host | link | global | NUMBER ]
FLAG-LIST := [ FLAG-LIST ] FLAG
FLAG := [ permanent | dynamic | secondary | primary |
tentative | deprecated ]La configuration de base d'une interface rÊseau ressemble à ceci :
# ifconfig eth0 192.168.0.2 netmask 255.255.255.0 broadcast 192.168.0.255
# route add default gw 192.168.0.1Les commandes Êquivalentes avec l'outil iproute2 sont les suivantes :
# ip addr add 192.168.0.2/24 dev eth0 brodcast 192.168.0.255
# ip route add default dev eth0 via 192.168.0.1IV-D. ip rule▲
Le routage du trafic IP a ÊtÊ complètement revu avec le noyau 2.2. Avant cette version, la prise de dÊcision ne se faisait qu'en consultant l'adresse de destination. Dans certaines circonstances, on peut souhaiter router les paquets IP en se basant sur d'autres champs : adresse source, champs TOS, etc.
Le routage est maintenant basÊ sur l'existence d'un ensemble de règles, qui dirigent le paquet vers des tables de routage. L'ensemble de ces règles est vu comme une base de donnÊes par le noyau, que l'on appelle Routing Policy DataBase (RPDB). Cette base de donnÊes de la politique de routage est en fait une liste linÊaire de règles ordonnÊes par une valeur numÊrique de prioritÊ. La gestion de ces règles se fait par l'intermÊdiaire de l'objet rule, dont voici la syntaxe :
Usage: ip rule [ list | add | del ] SELECTOR ACTION
SELECTOR := [ from PREFIX ] [ to PREFIX ] [ tos TOS ] [ fwmark FWMARK ]
[ dev STRING ] [ pref NUMBER ]
ACTION := [ table TABLE_ID ] [ nat ADDRESS ]
[ prohibit | reject | unreachable ]
[ realms [SRCREALM/]DSTREALM ]
TABLE_ID := [ local | main | default | NUMBER ]Chaque règle est constituĂŠe d'un sĂŠlecteur et d'une action. Quand le noyau a besoin de prendre une dĂŠcision sur le routage, la Routing Policy DataBase (RPDB) est scannĂŠe dans l'ordre des prioritĂŠs croissantes. Pour chaque paquet, on compare le sĂŠlecteur de la règle et l'en-tĂŞte du paquet. Sâil y a correspondance entre les deux, l'action est rĂŠalisĂŠe. En gĂŠnĂŠral, l'action consiste Ă se ÂŤÂ brancher  sur une table de routage qui contient l'information utile. Si l'action ne parvient pas Ă dĂŠterminer une route, alors la règle suivante est examinĂŠe. La commande suivante permet de lister l'ensemble des règles dĂŠfinies dans la base RPDB :
$ ip rule ls
0: from all lookup local
32766: from all lookup main
32767: from all lookup defaultCes lignes mÊritent quelques explications. Les chiffres de la colonne de gauche indiquent la prioritÊ de la règle. Ensuite, on a le sÊlecteur. Dans ce cas, toutes les règles seront appliquÊes à tous les paquets (from all). Enfin, on a l'action. Le mot-clÊ lookup indique d'aller regarder la table de routage dont le nom suit.
IV-E. ip route▲
Une fois que le noyau a sÊlectionnÊ la table à consulter, il recherche dans celle-ci les informations de routage proprement dites. Ces informations prÊcisent le pÊriphÊrique de sortie et Êventuellement l'adresse de la prochaine passerelle. Par dÊfaut, il y a trois tables de routage : local, main et default.
- local : cette table est une table un peu spÊciale ayant la plus grande prioritÊ. Elle contient les routes pour les adresses locales et les adresses de diffusion.
- main : cette table est la table de routage normale, et ce sont les informations contenues dans celle-ci qui seront affichÊes par la commande ip route ls.
- default : cette table est gÊnÊralement vide et n'est consultÊe que si les règles prÊcÊdentes n'ont pas sÊlectionnÊ le paquet.
La syntaxe associÊe à l'objet route est la suivante :
Usage: ip route { list | flush } SELECTOR
ip route get ADDRESS [ from ADDRESS iif STRING ]
[ oif STRING ] [ tos TOS ]
ip route { add | del | change | append | replace | monitor } ROUTE
SELECTOR := [ root PREFIX ] [ match PREFIX ] [ exact PREFIX ]
[ table TABLE_ID ] [ proto RTPROTO ]
[ type TYPE ] [ scope SCOPE ]
ROUTE := NODE_SPEC [ INFO_SPEC ]
NODE_SPEC := [ TYPE ] PREFIX [ tos TOS ]
[ table TABLE_ID ] [ proto RTPROTO ]
[ scope SCOPE ] [ metric METRIC ]
INFO_SPEC := NH OPTIONS FLAGS [ nexthop NH ]...
NH := [ via ADDRESS ] [ dev STRING ] [ weight NUMBER ] NHFLAGS
OPTIONS := FLAGS [ mtu NUMBER ] [ advmss NUMBER ]
[ rtt NUMBER ] [ rttvar NUMBER ]
[ window NUMBER] [ cwnd NUMBER ] [ ssthresh REALM ]
[ realms REALM ]
TYPE := [ unicast | local | broadcast | multicast | throw |
unreachable | prohibit | blackhole | nat ]
TABLE_ID := [ local | main | default | all | NUMBER ]
SCOPE := [ host | link | global | NUMBER ]
FLAGS := [ equalize ]
NHFLAGS := [ onlink | pervasive ]
RTPROTO := [ kernel | boot | static | NUMBER ]V. Configuration du filtrage▲
V-A. Introduction▲
La sÊcuritÊ informatique est un terme gÊnÊral qui cache de nombreux aspects, tels que la sÊcuritÊ physique de la machine, le contrôle d'accès aux fichiers, etc. L'un des aspects de la sÊcuritÊ concerne la sÊcuritÊ des rÊseaux. Avec la dÊmocratisation d'Internet, les tentatives d'intrusion se dÊveloppent. Afin de limiter le nombre de ces attaques, le mieux est encore de filtrer dès l'entrÊe du rÊseau tout ce qui n'est pas censÊ y entrer. Le système qui permet la mise en place de ce filtrage s'appelle un firewall ou un pare-feu en français.
Un firewall peut se dÊfinir comme un dispositif de protection (matÊriel et/ou logiciel) constituant un filtre entre un ordinateur ou un rÊseau local et un rÊseau non sÝr (Internet ou un autre rÊseau local par exemple). On distingue deux grandes familles de firewalls :
- Les firewalls basÊs sur le filtrage rÊseau. Ces ÊlÊments fonctionnent au niveau transmission de l'information des couches du modèle OSI. Le filtrage s'effectue en fonction des informations contenues dans les en-têtes des trames, des paquets (adresses source et destination) et des segments (ports source et destination). Ce type de filtrage ne s'intÊresse pas au contenu des paquets.
- Les firewalls applicatifs ou de services. Ce type de filtrage permet de contrĂ´ler le traitement de l'information. Dans ce cas, l'information contenue dans le paquet peut ĂŞtre prise en compte. Les demandes de connexions sont dirigĂŠes vers un programme spĂŠcial appelĂŠ mandataire ou proxy de service. C'est ce dernier qui ĂŠtablira la connexion vers le service extĂŠrieur demandĂŠ.
V-B. Netfilter et iptables▲
Pour pouvoir bÊnÊficier des fonctions de filtrage rÊseau du noyau LINUX, il faut y intÊgrer l'option Network packet filtering lors de la compilation. Cette fonctionnalitÊ est une structure gÊnÊrale qui permet à d'autres ÊlÊments de se  brancher  dessus. Pour pouvoir indiquer les diffÊrentes règles au noyau, on dispose de l'utilitaire appelÊ iptables.
L'outil iptables utilise le concept de tables de règles, chaque table correspondant à une fonctionnalitÊ d'examen du paquet. La table filter correspond au filtrage des paquets, la table nat concerne la traduction d'adresse et la table mangle permet la modification des paquets.
V-C. Utilisation de l'outil iptables▲
Dans un premier temps, iptables servira à la gestion des chaÎnes. Une chaÎne peut être assimilÊe à une politique de sÊcuritÊ associÊe à un flux de donnÊes. Par exemple, on peut dÊfinir une chaÎne INTERNET pour dÊsigner tous les flux venant de l'extÊrieur de votre rÊseau local. Trois chaÎnes par dÊfaut existent, à savoir INPUT, FORWARD et OUTPUT. Si le nombre de règles est limitÊ, on peut se contenter de celles-ci, mais si les règles deviennent consÊquentes, il est prÊfÊrable, pour faciliter la gestion, de crÊer de nouvelles chaÎnes. Les commandes de l'outil iptables associÊes à la gestion des chaÎnes sont les suivantes :
- -NÂ : CrĂŠation d'une nouvelle chaĂŽne. Exemple iptables -N INTERNET.
- -XÂ : Suppression d'une chaĂŽne vide. Exemple iptables -X INTERNET.
- -P : Mise en place de la règle par dÊfaut pour une chaÎne existante. Exemple : iptables -P INPUT DROP. Seules les chaÎnes INPUT, FORWARD et OUTPUT peuvent avoir une règle par dÊfaut et les seules cibles disponibles sont ACCEPT et DROP.
- -L : Lister les règles d'une chaÎne. Exemple : iptables -L INTERNET.
- -F : Effacer les règles d'une chaÎne. Exemple : iptables -F INTERNET.
Dans un deuxième temps, il convient de construire les règles à l'intÊrieur des diffÊrentes chaÎnes. L'ajout d'une règle s'effectue avec l'option -A de l'outil iptables, tandis que l'effacement d'une règle se fait avec l'option -D. Les principales spÊcifications sur lesquelles les règles peuvent s'appuyer sont les suivantes :
- -s : SpÊcifie l'adresse IP source.
- -d : SpÊcifie l'adresse IP de destination.
- -p : SpÊcifie le protocole. Le protocole peut être tcp, udp ou icmp.
- -i : SpÊcifie le nom de l'interface physique à travers laquelle les paquets entrent.
- -o : SpÊcifie le nom de l'interface physique à travers laquelle les paquets sortent.
Ces spĂŠcifications sont les plus gĂŠnĂŠrales, mais il en existe bien d'autres qui sont parfaitement listĂŠes dans la page de manuel de l'outil iptables.
V-D. Le filtrage avec iptables▲
Avec iptables, les diffÊrentes règles de filtrage sont organisÊes et regroupÊes dans des chaÎnes. Par dÊfaut, il y a trois chaÎnes appelÊes INPUT, OUTPUT et FORWARD. L'arrangement de ces chaÎnes est proposÊ sur le schÊma suivant :
_____
Incoming / \ Outgoing
-->[Routing ]--->|FORWARD|------->
[Decision] \_____/ ^
| |
v ____
___ / \
/ \ |OUTPUT|
|INPUT| \____/
\___/ ^
| |
----> Local Process ----
(c)2000 Rusty RussellLes diffÊrentes chaÎnes sont consultÊes selon la procÊdure suivante :
- Quand un paquet arrive, le noyau dÊcide de la destination de ce paquet : c'est la phase de routage.
- Si le paquet est destinĂŠ Ă la machine, le paquet descend dans le diagramme et la chaĂŽne INPUT est appliquĂŠe. Si le paquet passe cette chaĂŽne, celui-ci sera transmis Ă l'un des processus locaux.
- Si le routage dĂŠcide que le paquet est destinĂŠ Ă un autre rĂŠseau, alors c'est la chaĂŽne FORWARD qui est appliquĂŠe.
- Enfin, les paquets envoyĂŠs par un processus local seront examinĂŠs par la chaĂŽne OUTPUT. Si le paquet est acceptĂŠ, celui-ci sera envoyĂŠ, quelle que soit son interface de sortie.
Une chaÎne est composÊe d'une liste de règles. Une règle dÊcide de l'avenir d'un paquet en fonction de son en-tête. Les règles d'une chaÎne sont examinÊes les unes après les autres jusqu'à ce qu'une correspondance soit trouvÊe. Finalement, si aucune correspondance n'est trouvÊe, la règle par dÊfaut, policy, est appliquÊe. On associe à chaque règle une action à rÊaliser qui dÊcide de l'avenir du paquet. Les fonctions principales sont les suivantes :
- ACCEPTÂ : Cette cible permet d'accepter les paquets.
- DROPÂ : Cette cible permet de refuser les paquets sans avertir le demandeur que sa demande de connexion a ĂŠtĂŠ refusĂŠe.
- REJECTÂ : Cette cible permet de refuser les paquets, mais en avertissant le demandeur que sa demande de connexion a ĂŠtĂŠ refusĂŠe en lui envoyant un paquet RESET (RST).
V-E. Le suivi des communications, stateful firewalling▲
L'une des grandes nouveautÊs de la partie rÊseau du noyau 2.4 est la possibilitÊ du suivi des communications. Ceci fait rÊfÊrence à la capacitÊ du noyau à maintenir une table de suivi des communications en se basant, par exemple, sur le couple adresses (source et destination), sur les numÊros de ports (source et destination), sur les types de protocoles ou l'Êtat de la communication. Les pare-feux disposant de cette fonctionnalitÊ sont appelÊs stateful firewalls. Dans ce cas, les paquets sont inspectÊs dans le contexte d'une session. Par exemple, un segment TCP avec le bit ACK activÊ sera rejetÊ si aucun segment SYN correspondant n'a ÊtÊ reçu auparavant.
Le suivi des communications se base sur trois Êtats :
- NEWÂ : correspond Ă la demande de communication TCP initiale, au premier datagramme UDP ou au premier message ICMP.
- ESTABLISHED : si une entrÊe de la table de suivi des communications correspond, alors le paquet appartient à une communication de type ESTABLISHED. Dans le cas du protocole TCP, on se rÊfère au bit ACK après qu'une communication a ÊtÊ initiÊe. Dans le cas de datagrammes UDP c'est l'Êchange entre deux hôtes et les correspondances de numÊros de ports qui sont prises en compte. Enfin, les messages ICMP echo-reply doivent correspondre aux requêtes echo-request.
- RELATED : se rÊfère aux messages d'erreurs ICMP correspondant à une communication TCP ou UDP dÊjà prÊsente dans la table de suivi.
D'un point de vue pratique, le module de suivi des communications sera activÊ grâce à l'option -m state de la commande iptables. L'option --ctstate permet de spÊcifier l'Êtat de la communication à considÊrer.
# iptables -A INPUT -m conntrack --ctstate ESTABLISHED,RELATED -j ACCEPT
# iptables -A OUTPUT -p tcp -d 0/0 --dport 22 -m conntrack --ctstate NEW -j ACCEPTV-F. La traduction d'adresse (NAT)▲
La traduction d'adresse est une technique qui permet de remplacer une adresse source ou destination par une autre. La traduction d'adresse du noyau 2.4 supporte le source NAT (SNAT) et la destination NAT (DNAT). La table nat permet la modification des adresses source et destination grâce à deux chaÎnes par dÊfaut :
- PREROUTINGÂ : permet la modification de l'adresse de destination (DNAT) avant que le paquet ne passe par les fonctions de routage.
- POSTROUTING : permet la modification de l'adresse source (SNAT) après que le paquet soit passÊ par les fonctions de routage.
_____ _____
/ \ / \
PREROUTING -->[dĂŠcision]----------------->POSTROUTING----->
\D-NAT/ [de routage] \S-NAT/
----- | ^
| __|__
| / \
| | OUTPUT|
| \D-NAT/
| ^
| |
-------->Processus local------IntÊressons-nous dans un premier temps à la traduction d'adresse source ou S-NAT. Il existe en deux formes distinctes au sein des noyaux (2.4|2.6) : SNAT et MASQUERADE. SNAT est la forme standard de la traduction d'adresse source, tandis que la deuxième est plus spÊcialisÊe au cas d'adresses IP assignÊes dynamiquement. La distinction entre les deux formes est subtile.
Avec SNAT, la communication est maintenue pendant un certain temps d'attente lors d'un dysfonctionnement. Si cette communication est rĂŠtablie suffisamment rapidement, les programmes rĂŠseau ne seront pas affectĂŠs et le trafic TCP interrompu sera retransmis, dans la mesure oĂš l'adresse IP n'a pas ĂŠtĂŠ changĂŠe.
Avec la forme MASQUERADE, il n'y a pas de temps d'attente quand la connexion est rompue et les informations concernant la traduction d'adresse sont effacÊes. Ceci permet d'utiliser immÊdiatement la nouvelle adresse IP qui peut être attribuÊe lors d'une reconnexion à un fournisseur d'accès, par exemple.
# iptables -t nat -A POSTROUTING -o eth0 -j SNAT --to-source 192.192.192.192# iptables -t nat -A POSTROUTING -o ppp0 -j MASQUERADEVI. Remerciements Developpez▲
L'ĂŠquipe RĂŠseau remercie Philippe Latu et Laurent Foucher pour la rĂŠdaction de ce tutoriel.
Nos remerciements Ă Phanloga pour sa relecture orthographique.
N'hÊsitez pas à commenter cet article ! Commentez ![]()